常见的数据问题 知识点题库
后期处理技巧提升
|
班级 |
人数 |
图片后期处理(人) |
视频后期处理(人) |
音频后期处理(人) |
参与度 |
热度 |
|
高一一班 |
35 |
7 |
10 |
5 |
||
|
高一二班 |
40 |
12 |
10 |
11 |
||
|
高一三班 |
33 |
8 |
9 |
10 |
||
|
高一四班 |
38 |
10 |
12 |
0.8 |
||
|
高一五班 |
40 |
9 |
8 |
12 |
请分析任务,完成下列题目。
-
(1) 要计算高一班学生“后期处理技巧提升”调查的参与度,应该在F3单元格中输入的计算公式是 。A . =C3+D3+E3/B3 B . (C3+D3+E3)/B3 C . =(C3+D3+E3)/B3 D . SUM(C3+D3+E3)/B3
-
(2) 想要快速计算其他班级的“参与度”,按住F3单元格的 向下拖动即可。A . 边框 B . 自动填充句柄 C . 数据 D . 边框中间区域
-
(3) 现约定每个班级的“热度”就是该班“参与度”在年级中由高到低排序的序号。要得出“热度”榜单,需要以 为主要关键字进行降序排序。A . 班级 B . 人数 C . 参与度 D . 热度
-
(4) 为了直观反映出各班级参与度的高低,将数据可视化,最适合的图表类型是 。A . 雷达图 B . 柱形图 C . 折线图 D . 饼图
-
(5) 高一四班的“音频后期处理”统计处目前显示“0.8”,该数据出现的问题应属于 。A . 数据异常 B . 数据重复 C . 数据缺失 D . 格式不一致
|
图 a |
图 b |
-
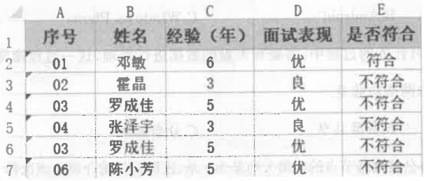
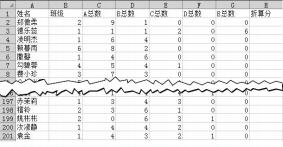
(1) 在对表格进行整理时发现,表格中关于“德乐蕊”的记录,可能存在的数据问题是 (选填:A .数据缺失/B .数据异常/C .逻辑错误/D .格式不一致)。
-
(2) “各班前5名统计.xlsx”文件中共有 位学生数据。
-
(3) 请在下述程序的划线处填上合适的代码。
Python 程序代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
df=pd.read_excel('学考成绩.xlsx')
#正常显示汉字
df.折算分=
#对df以“班级”为主要关键字升序、“A总数”为次要关键词降序进行排序
df_sort=df.sort_values(['班级', 'A 总数'], ascending=[True, False])
result=df_sort.head(5)
for i in range(2, 7):
result=result.append(df_sort[ ].head(5), ignore_index=True) result.to_excel('各班前5名统计.xlsx')
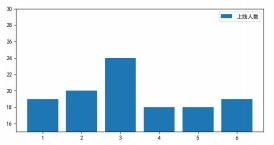
df=df[df.折算分>=92]
df_count=df.groupby('班级').count( )
#修改“折算分”列名为“上线人数”
df_count = df_count.rename(columns={'折算分':'上线人数'})
x=df count.indexy=
plt.figure(figsize=(8, 4))
plt.bar(x, y, label='上线人数')
plt.ylim(15, 30)
plt.legend( )
plt.show( )

-
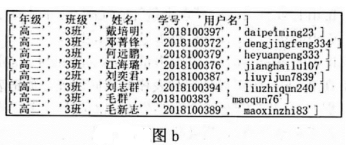
(1) 在数据整理时,常见的数据问题有( )(多选,选填字母)。A . 数据缺失 B . 数据重复 C . 逻辑错误 D . 格式不一致
-
(2) 实现上述功能的Python程序如下,请在划线处填入合适的代码。
a=[]
csv_file=open("xuehao.csv", "r", encoding='utf-8')
flines=csv_file. readlines() #将文件中所有数据按行读入flines中
csv_file. close() #关闭文件
# 将每个数据行中的各项信息以“,”作为分隔符切割成字符串存入列表a中
for line in flines:
tmp=list(line. strip("\n"). split(","))
a. append(tmp)
n=len(a)
i=1; m=n-1 #变量m表示删除重复数据后的实际数据个数
while i<n:
for j in range(m, i, -1):
if :
tmp=a[j]; a[j]=a[j-1]; a[j-1]=tmp
elif a[j][4]==a[j-1][4]:
a[j]=a[m]
i+=1
for i in range (m+1):
print (a[i])