文本数据的处理与可视化 知识点题库
①结果呈现②特征提取③分词④数据分析⑤文本数据获取
正确的顺序是( )

其中用作文本的特征项的是( )
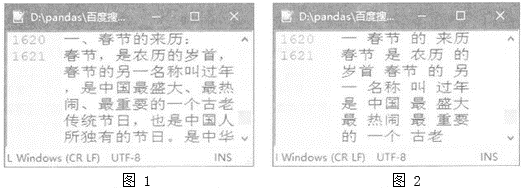
请回答下列问题:
-
(1) 文件chj.txt中的数据为(选填:“结构化数据”或“非结构化数据”)。
-
(2) 处理文件chj.txt中的数据生成chjfc.txt文件的过程,一般称为 。
-
(3) 编写如下Python程序,读取chjf.txt文件中的数据,并统计其中各词语(2个及以上文字构成)出现的次数。在划线处填写合适代码,完善程序。
txt = open('chjfc. txt', 'r', encoding='utf-8'). read( )
words-txt. split( )
word_ counts={ }
for word in words:
if len(word)==1:
continue
else:
① #可以为1行或多行代码
#使用word_counts计算词语word在words中出现的次数
word_ list=list(word_counts. items( )) #返回所有键值对信息,生成列表
word_ list. sort(key-lambda x:x[1], reverse=True) #按词语出现次数降序排序
for i in range(20):
word, times= ②
print(word, times)
程序中划线①处应填写的代码是
程序中划线②处应填写的代码是
-
(4) 去除步骤(3)程序的统计结果中的非特征词(如代词介词连词等)后,制作的标签云如图所示,标签云中最能表现文件chj.txt中文本特征的词有(写出3~5个)。

①搜索引擎②自动摘要③论文查重④成绩查询⑤自动应答

data. txt 记事本
他处理“data.txt”文件中英文单词的Python程序段如下:
file='data.txt'
word_ c=[]
n=0
for word in open(file):
if word[0:1]=='c':
word_c. append(word)
print(word)
print('字母c开头的单词个数:',n)
-
(1) 划线处的代码为。
-
(2) 该程序段运行后,列表word_c中的数据为。

-
(1) 图1中单词的间隔有 。
-
(2) 自定义函数cleantext( )的功能是。
-
(3) 在划线处填入合适代码,完善程序。
import pandas as pd
def cleantext( ):
txt = open("textbook.txt","r"). read( )
txt= ① #将字符串中所有大写字母转为小写
for ch in '! ( );:''',.? ' :
txt = txt.replace(ch,"") #用空格替代ch的值
return txt
booktxt = cleantext( )
words = booktxt. split( )
#以空格为分隔符分割文本并生成列表
counts= { }
for word in words:
counts[word]=counts. get( word,0)+1
items= -list(counts. items( )) #返回所有键值对信息,生成列表
df= pd.DataFrame(items,columns=['word','times'])
df1= df.sort _values('word')
df1.plot( x='word', y='times', kind='line', igsize=(8,3))
df2= ②
print('文件中出现的不同单词数:', ③ )
print(df2[:10])
① ② ③
-
(4) 运行程序,输出结果如图2所示,绘制的图形如图3所示。结合两图分析,该教材中出现次数超过50次的单词有哪些?这些单词有什么特征?
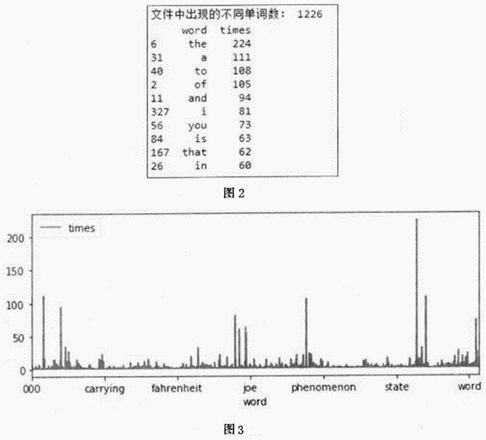
-
(5) 若将该教材中单词的掌握程度分为“非常熟练”“熟练”“一般”三类输 出,请完善下表。
掌握程度
程序末尾须添加的输出语句
非常熟练(出现10次以上)
熟练(出现2~10次)
一般(出现1次)

①分词 ②特征提取 ③数据分析 ④结果呈现

-
(1) 组织字典中的单词,链表相比较数组的优势有 (单选,填字母:A .可快速查找任何一个单词/ B .存储空间少/ C .插入、删除操作无需频繁移动单词)
-
(2) 实现上述功能的部分Python 程序如下,请在划线处填入合适的代码。
word = ["yellow", "accent", "call", "excel", "tea", "little", "brother"] #存储结点的数据区域
turn = [4,-1,6,2,5,3,1] #存储结点的指针区域
del_word = input("请输入要删除的单词:")
head = 0 #头指针为head
pre_point = -1
while point != -1:
if :
point = turn[point]
break #break退出当前循环
pre_point = point
point = turn[point]
if pre_point == -1: #删除头节点
head = point
elif point == -1: #删除尾节点
turn[pre_point] = -1
else:
turn[pre_point] = point
point = head
print("删除单词后词典为:")
while point != -1:
print(word[point],end=" ")
print('\n')


import import import
pandas as pd
os,jieba,re,random,wordcloud
matplotlib.pyplot as plt
from PIL import Image
wzdir = "./2021 浙江高考满分作文/"
wz = os.listdir(wzdir) #获得文件夹中所有文件的名称列表
wzrd = ①
f=open(wzdir+wzrd[0],encoding="utf-8")
dd=f.read ()
f.close()
#使用正则表达式去除文章中的标点符号
ss = re.sub("[、,。:“”;?\n]","",dd)
wb = jieba.lcut(ss,cut_all=True)
word = {}
for i in wb:
t =i.strip()
if len(t)>1:
if t in word:
word[t]+=1
else:
②
wc = wordcloud.WordCloud(font_path="msyh.ttc", width=800, height=600) wc.background_color="white"
wc.fit_words (word)
img = wc.to_array()
plt.rcParams['font.sans-serif']=['SimHei'] plt.figure()
plt.imshow(img)
plt.axis(False)
plt.title(wzrd[0].split(".")[0])
③
#支持中文显示
-
(1) 为实现上述功能①处代码为A . random.sample(wz,1) B . random.shuffle(wz) C . random.randint(1,10)
-
(2) 请将②③处代码补充完整
②③



