数据管理 知识点题库
| 货号 | 品名 | 数量 | 金额 | 流水号 |
| 398626 | 老酸奶 | 3 | 15 | 201607290093 |
| 986712 | 牛里脊 | 1.26 | 138.6 | 201608020032 |
| 486134 | 西蓝花 | 0.505 | 6.056.05 | 201609130065 |
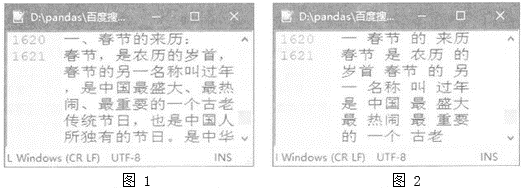
请回答下列问题:
-
(1) 文件chj.txt中的数据为(选填:“结构化数据”或“非结构化数据”)。
-
(2) 处理文件chj.txt中的数据生成chjfc.txt文件的过程,一般称为 。
-
(3) 编写如下Python程序,读取chjf.txt文件中的数据,并统计其中各词语(2个及以上文字构成)出现的次数。在划线处填写合适代码,完善程序。
txt = open('chjfc. txt', 'r', encoding='utf-8'). read( )
words-txt. split( )
word_ counts={ }
for word in words:
if len(word)==1:
continue
else:
① #可以为1行或多行代码
#使用word_counts计算词语word在words中出现的次数
word_ list=list(word_counts. items( )) #返回所有键值对信息,生成列表
word_ list. sort(key-lambda x:x[1], reverse=True) #按词语出现次数降序排序
for i in range(20):
word, times= ②
print(word, times)
程序中划线①处应填写的代码是
程序中划线②处应填写的代码是
-
(4) 去除步骤(3)程序的统计结果中的非特征词(如代词介词连词等)后,制作的标签云如图所示,标签云中最能表现文件chj.txt中文本特征的词有(写出3~5个)。

[项目情境]
唐代诗人史传有名有姓者不下千余人,他们组成了大大小小不同的朋友圈。有的因为诗风接近,如李白代表的浪漫主义、杜甫代表的现实主义、王维代表的田园山水、芩参代表的边塞诗风;有的因为年龄大体相近,如盛唐时期的李白、杜甫、贺知章等;有的因为政见相近,如韩愈作为古文运动的领袖级人物,当时很多文人墨客以进人他的朋友圈为荣。在盛唐时期有这样一个朋友圈,他们的友谊跨越数十年,诗人之间通过互动诗歌,表达、抒发情感,是他们朋友圈的一种表现方式,用计算机来分析这个时代的唐诗,就会发现诗人之间有着你意想不到的千丝万缕的关系。学校某研究性学习小组利用大数据分析技术,通过对诗词分析,绘制盛唐时期几位诗人(杜甫、李白、王维、孟浩然……)之间的社交关系网络图,试图推测哪位诗人是同时代诗人的核心,哪位诗人的影响最大,从而更好地学习、理解唐诗。
[项目准备]为完成项目,需要确定主题、目标、制订规划等各项工作。在此不一一展示。明确的主题——盛唐时期的诗人及诗词分析和诗人社交关系网络图
[项目实施]项目研究主要以诗人诗作为依据。具体实施过程如下:
-
(1) 明确需要采集的数据,选择合适的采集途径、工具和方法。
全唐诗一共四万多首,分析采集相关数据的条件:①盛唐时期;②诗人、诗人之间经常称呼对方的别名;③考虑到同名同姓的问题,因此还需要诗人的生卒年的信息。
根据要求,完成答题。
①全唐诗数量较多,一共四万多首,来源分散,存储在互联网不同的服务器与各客户终端。从大数据存储与计算的角度来看,由此可知大数据具有的特征。(单选)
A.精确让位于模糊
B.价值密度低
C.分布式存储
D.变化速度快
②网络上如此海量的关于唐诗的数据,有文字图片、视频、音频等。这些数据种类和格式也不一致,表明各种数据共存于网络中。(多选)
A.结构化
B.半结构化
C.非结构化
D.网状结构
③面对繁杂的数据,学习小组决定研究解密盛唐时期诗人关系,并利用计算机程序从网络中采集诗人别名等相关的文本数据,并以一定的数据结构存储,形成盛唐诗库。存储数据主要有两种方式,一种是,一种是数据云存储。你建议学习小组采用数据存储方式,理由是。
-
(2) 利用Python程序采集、整理、分析数据。
第一步,从互联网中筛选出符合条件的诗人及诗作等文本,整理并形成盛唐诗库;第二步,确定人物关系分析策略,即从唐诗库中搜索、统计诗人或别名的引用次数,确定二人之间的疏密关系,规则是诗的标题和正文中只要提到过对方,那么两者之间的引用关系加1,若一首诗中提到多次对方,只算一次引用;第三步,编写程序并调试验证。
用爬虫程序段(如下图所示)采集数据。根据要求,完成答题。
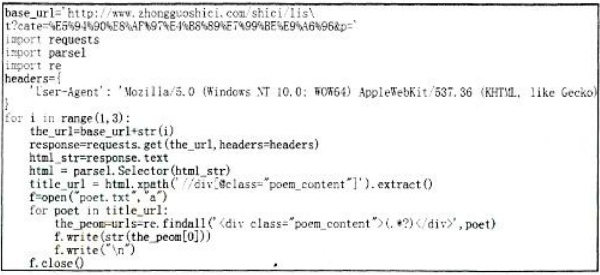
使用爬虫程序获取文本数据并形成唐诗库文件,所使用的数据采集方法为(选填:系统日志采集法、网络数据采集法、其他数据采集方法)。阅读程序可知,每首诗存放于列表poem[ ]中(以唐诗“春晓”为例,如下表),采集后的数据保存在poet.txt文件中,该文件是一个(选填:数据库文件、文档文件、图像文件、网页文件)。该数据采集方法可以将非结构化数据从网页中抽取出来,将其存储为统一的数据文件,并以化的方式存储(选填:结构化、半结构化)。
Poem[0]
Poem[1]
Poem[2]
Poem[3]
“春晓”
“唐"
“孟浩然”
“春眠不觉晓……花落知多少”
以诗人甲,乙为例,解密二人关系。根据要求,完成答题。

①数据处理过程中要运用一定的分析方法对大量、无序的数据进行整理、分析,挖掘数据内在的结构和规律,从而提取有价值的、有意义的数据。数据分析一般包括特征探索、关联分析、聚类与分类等。让计算机搜索遍历唐诗库中有关甲,乙两位诗人的诗文,统计两位诗,人或别名相互的引用次数,找寻二人之间的关联。这是运用了(选填:特征探索、关联分析、聚类与分类)方法进行数据分析,也是(选填:枚举、二分查找、排序)算法思想去求解这一问题的体现。
②编制计算机程序解决问题的过程中,是编程的核心, 是解决问题的方法和步骤。选用Python程序设计语言编写程序,Python属于(选填:分析问题、设计算法、编写程序、调试运行、机器语言、汇编语言高级语言)。图a示意,使用 (选填:自然语言、流程图、伪代码)进行算法描述,且运用循环控制结构嵌套了控制结构,如果要跳出本次循环体的执行,应使用语句实现跳转。
③阅读程序(图b示意),程序中以“#”开头的语句,其作用是,程序调试完成,通过“另存为”保存文件,文件后缀名为。
-
(3) 分析数据,进行可视化表达,并推测盛唐时期诗人关系。
解密盛唐时期诗人关系。根据要求,完成答题。
①数据的可视化以易于理解的方式展示和诠释数据之间的关系、趋势与规律等,使人们更好地理解数据。从常用和实用的维度,数据可视化的呈现类型主要分为探索型和解释型,其中型可以帮助人们发现数据背后的价值,型则把数据简单明了地解释给人们(选填:探索、解释)。数据分析类型不同可视化呈现方式也不同,如关于趋势的分析,可用类型的图表呈现,关于比例的分析,可用类型的图表呈现,关于关系的分析,可用类型的图表呈现。
②学习小组选择用网络关系图呈现盛唐时期诗人社会网络关系(如图所示)。图中,箭头表示诗人之间的引用关系,如李白引用了贺知章,那么就有李白指向贺知章箭头;箭头的粗细程度则表示了诗人之间引用关系的强弱,如李白引用孟浩然的数量达4次,箭头就要粗一些。
③观察图示,从绘制的盛唐的诗人社交关系网络图,尝试推测哪位诗人是盛唐诗人的核心,哪位诗人的影响最大,请简要阐述。(要求100字左右)
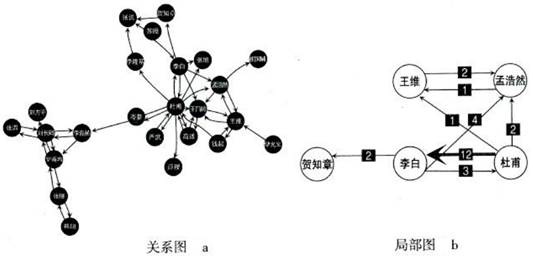
④通过对该项目案例的研究学习,请谈谈大数据对学习生活的影响。

【项目情境】
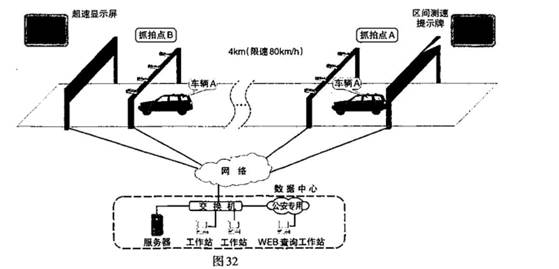
为了进一步提高交通管理水平,加大对超速违法行为的管控力度,保证高速公路行驶安全,打击违章超速等行为,高速公路上设置了多种测速方式,区间测速是常见的测速方式之一(如下图),某高速路段测速区间距离为4公里,该路段限速每小时80公里,车辆通过此路段的时间超过3分钟,则其平均时速就符合限速要求:车辆通过此路段的时间不足3分钟,就说明该车辆已经超速。
【项目规划】
为完成项目,需要经历确定主题、明确目标、项目方案设计等过程。项目预期成果为设计Python程序模拟区间测速。
【项目实施】具体实施过程如下:
㈠上网收集并整理资料,明确区间测速的工作原理和使用现状
资料一:区间测速的工作原理是选择恒定限速值路段,在起始点和结束点布设摄像机建立监控抓拍系统,基于车辆通过前后两个监控点的时间,计算车辆在该路段上的平均行驶速度,并依据该路段限速标准判定车辆是否超速。当车辆进入测速区时,区间测速设备会测试3个速度:进出点位的瞬时车速和通过路段的平均时速,如果3个速度中,多次出现超速,则取最高值进行处罚。此外,该系统具有数据(车辆行驶速度、交通流量、车辆的牌照号码、颜色、物理大概尺寸以及驾驶员特征)采集、号牌识别、时钟同步、平均速度计算、车型限速值判定、违法行为自动甄别、图像取证等诸多功能。
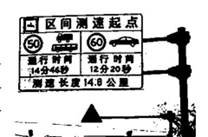
资料二:2013年2月5日,江苏正式启用了高速公路机动车全程区间测速系统。江苏省公安厅交巡警总队称,在沪宁高速南京至常州、宁杭高速南京至溧阳两个试点路段内,共抓拍到机动车超速违法行为3.3万余起,超速行驶同比下降30%。
阅读资料,根据要求,回答问题。
-
(1) 小组成员通过搜索引擎检索、下载相关资料,并运用WPS软件整理形成资料一和资料二。搜索引擎属于,WPS软件属于选填(信息检索工具/三维设计工具/信息加工工具)
-
(2) 根据资料一表明,区间测速是通过监控抓拍系统实现的。系统通过摄像头抓拍到的数据有 (至少写出三种),其记录形式是多样的、可看的、可听的、可感知的。这些数据可以是表示事物的属性、数量、位置的数值性符号,也可以是图形图像等性符号,计算机对这些数据进行号牌识别、平均速度计算、车型限速值判定等,然后再转换成视、听、触等我们可感知的交通违法车辆信息。
-
(3) 小组成员通过对区间测速原理的分析得知:一是区间测速通过公式
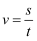 (s表示测速路段长度,t表示两个摄像头抓拍到同一车辆的时间差)准确测得车辆通过测速路段的平均车速。二是从运动学意义角度获悉:曲线运动在任意一个运动过程中至少存在一个位置(或一个时刻)的瞬时速率等于这个过程中的平均速率。由此,请分析知识获得的途径。
(s表示测速路段长度,t表示两个摄像头抓拍到同一车辆的时间差)准确测得车辆通过测速路段的平均车速。二是从运动学意义角度获悉:曲线运动在任意一个运动过程中至少存在一个位置(或一个时刻)的瞬时速率等于这个过程中的平均速率。由此,请分析知识获得的途径。
-
(4) 由资料二获知,对车辆予以抓拍、取证后的数据,通过网络传输到公安交通指挥中心和交通控制分中心的数据库中进行数据存储查询、比对等处理,最终形成的信息成为交管部门用于对违法、违规车辆进行处罚的法律依据。分析资料二,谈谈在大数据时代,你对数据的理解与认识。
|
图1 |

-
(1) “票房前100名.xlsx”属于(填字母:A .结构化\ B .非结构化 \ C .半结构化)数据。
-
(2) 如想要筛选得到该表内复仇者联盟各部剧的信息,以下可以操作的是 (多选题)A .
 B .
B .  C .
C .  D .
D . 
-
(3) 要用Python实现如图2所示图表,代码如下,请在程序①②③划线处填入合适的代码。
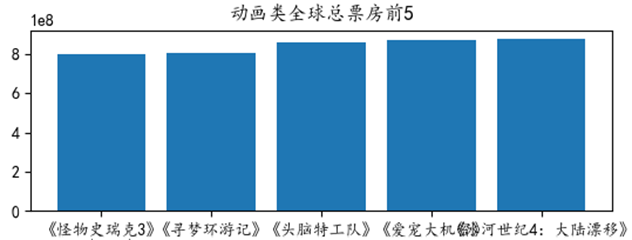
图2
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("票房前100名.xlsx")
yplx=input("输入影片类型:")
df1= df[] #对df取某类型电影的数据
df2=df1.sort_values("总票房",ascengding=False). #按总票房降序并取前5名
x=df2["影片名"]
y=
plt.bar(x,y)
plt.title(yplx+"类全球总票房前5") #设置图标题
plt.show() #显示图



