数据表、字段、记录的编辑 知识点题库

 B .
B . 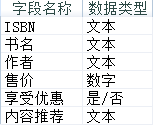 C .
C . 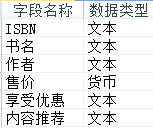 D .
D . 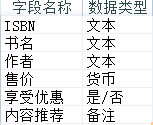

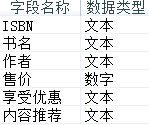
以下关于该数据表说法正确的是( )

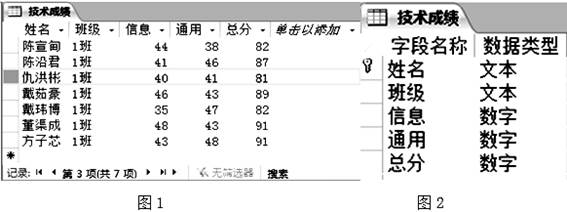


用户信息相关的数据库使用Access设计,下列说法不正确的是( )

在录入数据时,下列说法不正确的是( )


以下说法正确的是( )

下列说法正确的是( )

| 会员编号 | 姓名 | 积分 | 性别 | 余额 | 出生日期 |
| V101 | 张小明 | 461 | 男 | ¥820.0 | 1999-12-21 |
| P103 | 李小红 | 5000 | 女 | ¥786.0 | 2000-01-24 |
| …… | …… | …… | …… | …… | …… |
若用Access数据表“会员信息”来存储上述表的信息,下列说法错误的是( )


| 学号 | 姓名 | 到校时间 | 离校时间 | 状态 |
| 2020050101 | 陈芸 | 2021/5/10 6:50 | 2021/5/10 11:55 | 正常 |
| 2020050903 | 刘晓东 | 2021/5/10 6:54 | 2021/5/10 10:55 | 异常 |
| 2020050324 | 钱宇 | 2021/5/10 7:13 | 2021/5/10 10:55 | 异常 |
| 2020050903 | 刘晓东 | 2021/5/10 13:13 | 2021/5/10 17:02 | 正常 |
| …… | …… | …… | …… | …… |
| 序号 | 疫苗编号 | 疫苗名称 | 生产厂商 | 入库/出库 | 数量 |
| R001 | MH098734 | 灭活疫苗 | 国药武汉生物 | 入库 | 5000 |
| R002 | MH076321 | 灭活疫苗 | 北京科兴 | 入库 | 15000 |
| C001 | MH098734 | 灭活疫苗 | 北京科兴 | 出库 | 6800 |
| R003 | CZ0102568 | 重组新冠病毒疫苗 | 康希诺 | 入库 | 10000 |
| … | … | … | … | … | … |
下列关于“疫苗入库出库”数据表的描述,错误的是( )
办公用品入库单
|
物资编号 |
物资名称 |
单位 |
单价 |
入库数量 |
入库日期 |
审核 |
|
105201 |
铅笔 |
支 |
¥0.80 |
500 |
2021/6/21 |
已审核 |
|
105202 |
钢笔 |
支 |
¥75.00 |
100 |
2021/6/21 |
未审核 |
|
305203 |
美工刀 |
把 |
¥5.00 |
160 |
2021/6/21 |
已审核 |
|
405204 |
橡皮 |
块 |
¥2.00 |
200 |
2021/6/21 |
已审核 |

下列关于“物资入库”数据表的描述,正确的是( )
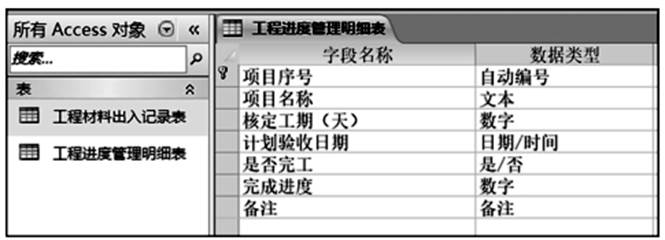
下列说法正确的是( )

-
(1) 小明对数据进行了整理,下列操作不恰当的是( )(单选,填字母)。A . 发现记录中有6 条重复,对这6 条记录进行了删除 B . 发现记录中有38 处数据项缺失,直接删除相关记录 C . 将某条记录中订单日期“2050-6-9”订正为“2021-6-9” D . 将某条记录中订单日期“2021#3#11”修改为“2021-3-11”
-
(2) 小明发现数据中仍有极少量时间段外的记录混杂其中,利用Python 及pandas 模块进行处理。请回答问题:
① 采用pandas 模块中的(单选:填字母:A .Series / B .DataFrame)
数据结构存储全部数据会比较高效。
② 全部数据保存于变量df 中,为筛选出订单日期为2021 年第一季度内的所有记录,
可以执行Python 语句df1 = ,则df1 中保存筛选结果。(单选,填字母。
提示:多条件筛选时,条件之间用“&”连接,表示需要同时满足这多个条件)
A.df[ (df['订单日期'] <= '2021-1-1' ) & (df ['订单日期'] <= '2021-3-31') ]
B.df [ (df ['订单日期'] >= '2021-1-1') & (df ['订单日期'] >= '2021-3-31') ]
C.df [(df ['订单日期'] >= '2021-1-1') & (df ['订单日期'] <= '2021-3-31')]
-
(3) 经过以上两步处理之后,为了解“所在地市”第一季度“订购数量”前10 名的情况,
编写如下Python 程序段:
#数据整理结果保存于变量df1中,代码略
g = df1.groupby('所在地市', as_index = False).sum()
print )

则划线处的代码可为( )(多选,填字母)
A . g.sort_values('订购数量',ascending = False) [0:10] B . g.sort_values('订购数量',ascending = True).tail(10) C . g.sort_values('订购数量',ascending = True)[0:10] D . g.sort_values('订购数量',ascending = False).head(10) -
(4) 根据以上数据整理结果,小明对第一季度所在地市的“订购数量”进行可视化处理,如图b所示。
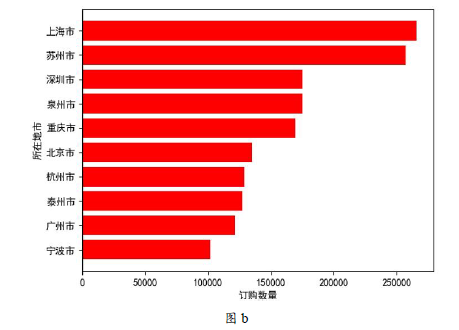
实现上述功能的Python程序部分代码如下:
#按“所在地市”对第一季度数据分组并求和,再按“订购数量”升序排序
#选取最后10条数据,存入变量s,代码略
import matplotlib.pyplot as plt
x = s['所在地市']
y =
plt.barh(x, y, color = 'r')
plt.show( )
程序中划线处代码应为。
-
(5) 小明借助大数据技术,对近几年来该网络购物平台的日用化妆品销售数据进行了分析。
应用该分析结果可能提供的数据服务是(列举一条即可)。



