5.4.1 数据可视化表达的方式 知识点题库
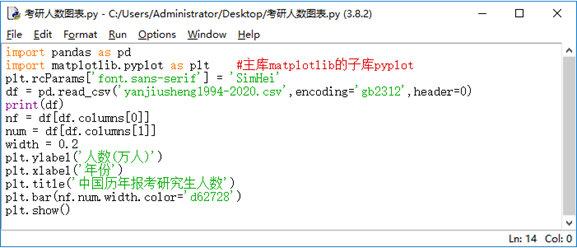
-
(1) 本程序中引用了第三方库,写出库名称,从代码中找出来。
-
(2) 本程序读取了数据文件,文件名称是什么?
-
(3) 读取数据文件的数据赋值到二维表型数据结构对象中,这个对象的名称是什么?
-
(4) 本程序实现了数据可视化,呈现的图表为柱形图、折线图还是散点图?通过哪行代码来实现?
-
(5) 本程序文件实现的图表的标题是什么?阅读程序,从其中找出来。
① ②
实现功能:绘制y=x2-2x+ 1的图像
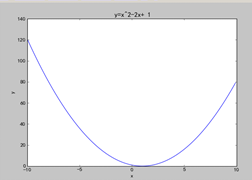
#加载numpy模块并限简洁的别名为np
import numpy as np
#加载matplotlib.pyplot模块并限简洁的别名为plt
import matplotlib.pyplot as plt
#x在-7到9之间,每隔0.1取一个点
x=np.arange(-7,9,0.1)
= x**2-2*x+1
plt.plot(x,)
plt.title('y=x*x-2*x+1')
plt.xlabel('x')
plt.ylabel('y')
plt.

-
(1) 根据H3单元格中的公式可以推算出I3中单元格公式为。
-
(2) 若在某次修改后,C列部分显示内容为“###”,则可能的原因是。
-
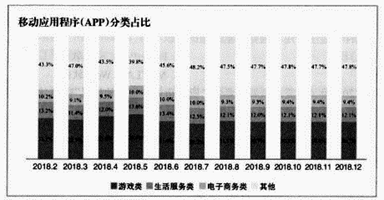
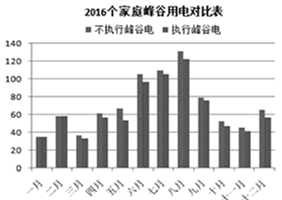
(3) 为了更直观地反映执行峰谷电和不执行峰谷电之间的变化,小赵创建了如下图所示的柱形图表,该图表的数据区域为。
-
(4) 小赵对区域A2:I14数据按“总电量”进行排序,是否(选填:会/不会)对柱形图表效果产生影响。


-
(1) 在以上Python程序中,变量Y的数据类型是。
-
(2) 在以上Python程序中,第8行横线处的代码是。
-
(3) 通过观察,气温釆样间隔时间是个小时。

|
图a |
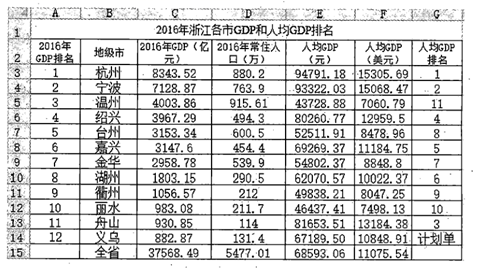
请回答下列问题:
-
(1) 区域E3:E14的数据是通过公式计算得到的,并用自动填充功能完成区域E4:E14的计算,则E3单元格中的公式是。
-
(2) 小张操作时不小心删除了D3单元格的内容,则E3显示的内容是(填A . #DIV/0!/B . #VALUE!/C . #REF!)。
-
(3) 根据图a中数据,小张制作了一张图表,如图b所示,创建该图表的数据区域是。

图b
-
(4) 将区域A2:G14的数据复制到新工作表,在新工作表中相关数据进行筛选操作,筛选设置如图c所示,则按此设置筛选出的城市有个。
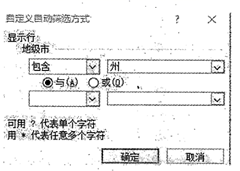
图c

-
(1) 若将上图表格中的F3:F11数据格式设置为两位小数,则单元格F12中的数据(选填:会/不会)发生改变。
-
(2) 将上图表格中的区域A1:G11的数据复制到新工作表中,在新工作表中对“数量”和“利润”两列数据进行筛选操作,筛选设置均如下图所示,则筛选出的水果名称为。
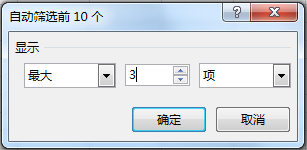
-
(3) 根据表格中的数据制作图表如下图所示,则该图表的数据区域为。
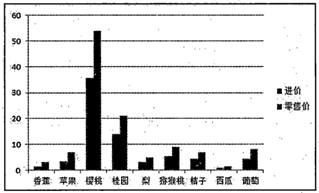
-
(4) 根据“利润”列数据,用RANK函数和自动填充功能,在区域G3:G11中计算各水果利润的名次,则G3中的公式为。
(提示:RANK函数用于计算某数字在一列数字中相对于其他数字的大小排名。例如:=RANK(A3,$A$3:$A$11)表示A3单元格中的数字在A3:A11中的排名)

请回答下列问题:
-
(1) 区域G3:G31的数据是在G3单元格输入公式后,通过自动填充实现计算,则G3单元格中的公式应为
-
(2) 设置如图b所示的筛选条件,下列地区中能显示的是 (单选,填字母)
①温州②甘孜州③黔东南州④湘西自治州⑤万州区
 A . ①② B . ①⑤ C . ②⑤ D . ③④
A . ①② B . ①⑤ C . ②⑤ D . ③④ -
(3) 为了解各省市入围情况,绘制图表如图c所示,结合图a和图c,下列说法正确的是 (多选,填字母)。
 A . 修改B列城市名,图表不会发生变化 B . 在图a所示工作表的G列前插入一列,图表不会发生变化 C . 对A2:C434区域,按“省份”筛选浙江省,图表会发生变化 D . 对A2:C434区域,按“省份”为主要关键字进行升序排序,图表会发生变化
A . 修改B列城市名,图表不会发生变化 B . 在图a所示工作表的G列前插入一列,图表不会发生变化 C . 对A2:C434区域,按“省份”筛选浙江省,图表会发生变化 D . 对A2:C434区域,按“省份”为主要关键字进行升序排序,图表会发生变化
 图a
图a
请回答下列问题:
-
(1) 区域E4:E8的数据是通过公式计算得到的,在E4单元格中输入公式,再使用自动填充功能完成区域E5:E8的计算。
-
(2) 利用“设置单元格格式”将E列数值设置保留1位小数后,以“住户用电量占年总耗电量比%”为主要关键字,以“住户”为次要关键字,将A4:J8单元格区域内数据进行降序排序,则2019年数据所在行标值为。
-
(3) 为了反映2016~2020年我国水消耗量变化情况,根据图a中的数据创作的图表如图b所示。综合图a和图b,下列说法正确的有( )(多选,填字母)。
 图bA . 创建该图表的数据区域为A2:A8,J2:J8 B . 2016~2019年间水消耗量逐年递增,2020年出现下降情况 C . 要分别筛选出五年内“汽油”和“液化石油气”消耗量最高年份,可同时对H、I列设置筛选条件“最大的一项” D . 交换C列和D列的数据位置,会影响E列数据值的计算
图bA . 创建该图表的数据区域为A2:A8,J2:J8 B . 2016~2019年间水消耗量逐年递增,2020年出现下降情况 C . 要分别筛选出五年内“汽油”和“液化石油气”消耗量最高年份,可同时对H、I列设置筛选条件“最大的一项” D . 交换C列和D列的数据位置,会影响E列数据值的计算

-
(1) 小明对数据进行了整理,下列操作不恰当的是( )(单选,填字母)。A . 发现记录中有6 条重复,对这6 条记录进行了删除 B . 发现记录中有38 处数据项缺失,直接删除相关记录 C . 将某条记录中订单日期“2050-6-9”订正为“2021-6-9” D . 将某条记录中订单日期“2021#3#11”修改为“2021-3-11”
-
(2) 小明发现数据中仍有极少量时间段外的记录混杂其中,利用Python 及pandas 模块进行处理。请回答问题:
① 采用pandas 模块中的(单选:填字母:A .Series / B .DataFrame)
数据结构存储全部数据会比较高效。
② 全部数据保存于变量df 中,为筛选出订单日期为2021 年第一季度内的所有记录,
可以执行Python 语句df1 = ,则df1 中保存筛选结果。(单选,填字母。
提示:多条件筛选时,条件之间用“&”连接,表示需要同时满足这多个条件)
A.df[ (df['订单日期'] <= '2021-1-1' ) & (df ['订单日期'] <= '2021-3-31') ]
B.df [ (df ['订单日期'] >= '2021-1-1') & (df ['订单日期'] >= '2021-3-31') ]
C.df [(df ['订单日期'] >= '2021-1-1') & (df ['订单日期'] <= '2021-3-31')]
-
(3) 经过以上两步处理之后,为了解“所在地市”第一季度“订购数量”前10 名的情况,
编写如下Python 程序段:
#数据整理结果保存于变量df1中,代码略
g = df1.groupby('所在地市', as_index = False).sum()
print )

则划线处的代码可为( )(多选,填字母)
A . g.sort_values('订购数量',ascending = False) [0:10] B . g.sort_values('订购数量',ascending = True).tail(10) C . g.sort_values('订购数量',ascending = True)[0:10] D . g.sort_values('订购数量',ascending = False).head(10) -
(4) 根据以上数据整理结果,小明对第一季度所在地市的“订购数量”进行可视化处理,如图b所示。
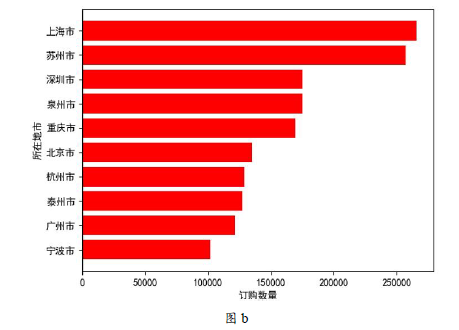
实现上述功能的Python程序部分代码如下:
#按“所在地市”对第一季度数据分组并求和,再按“订购数量”升序排序
#选取最后10条数据,存入变量s,代码略
import matplotlib.pyplot as plt
x = s['所在地市']
y =
plt.barh(x, y, color = 'r')
plt.show( )
程序中划线处代码应为。
-
(5) 小明借助大数据技术,对近几年来该网络购物平台的日用化妆品销售数据进行了分析。
应用该分析结果可能提供的数据服务是(列举一条即可)。
|
图 a |
图 b |
-
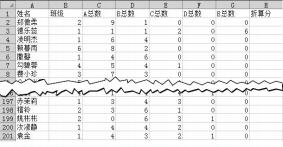
(1) 在对表格进行整理时发现,表格中关于“德乐蕊”的记录,可能存在的数据问题是 (选填:A .数据缺失/B .数据异常/C .逻辑错误/D .格式不一致)。
-
(2) “各班前5名统计.xlsx”文件中共有 位学生数据。
-
(3) 请在下述程序的划线处填上合适的代码。
Python 程序代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
df=pd.read_excel('学考成绩.xlsx')
#正常显示汉字
df.折算分=
#对df以“班级”为主要关键字升序、“A总数”为次要关键词降序进行排序
df_sort=df.sort_values(['班级', 'A 总数'], ascending=[True, False])
result=df_sort.head(5)
for i in range(2, 7):
result=result.append(df_sort[ ].head(5), ignore_index=True) result.to_excel('各班前5名统计.xlsx')
df=df[df.折算分>=92]
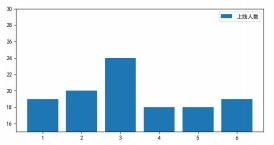
df_count=df.groupby('班级').count( )
#修改“折算分”列名为“上线人数”
df_count = df_count.rename(columns={'折算分':'上线人数'})
x=df count.indexy=
plt.figure(figsize=(8, 4))
plt.bar(x, y, label='上线人数')
plt.ylim(15, 30)
plt.legend( )
plt.show( )



