编程处理数据与可视化 知识点题库
import matplotlib.pyplot as plt
import numpy as np
# numpylinspace(start, stop, num=50)
#产生从start到stop的等差数列,num为元素个数,默认50个
x = np. linspace(-1,1,50)
forn in [1/3,1/2,1,2,3]:
y=x**n
plt. show( )
请回答下面问题:
-
(1) 划线处应填写的语句是。
-
(2) 程序运行后,绘制了个函数的图象,分别为。

data. txt 记事本
他处理“data.txt”文件中英文单词的Python程序段如下:
file='data.txt'
word_ c=[]
n=0
for word in open(file):
if word[0:1]=='c':
word_c. append(word)
print(word)
print('字母c开头的单词个数:',n)
-
(1) 划线处的代码为。
-
(2) 该程序段运行后,列表word_c中的数据为。
from microbit import sleep #导入microbit函数库
import dht11
while True:
temp, hum= <dht11.read(2) #获取传感器的温度和湿度数据
print("temp = %d C" %temp)
print("bum = ", hum)
sleep(100) #等待
下列说法正确的是( )
-
(1) 采集后的数据是一个有序的文本数据,系统根据关键字进行搜索,并将搜索到的时间和留言内容保存到result数据表中。请你为该数据表设计字段,写出至少3个字段名称及其数据类型。
字段名
数据类型
备注
-
(2) 编写FlaskWeb框架的Python程序,实现输入关键字,单击“搜索”按钮,显示result数据表中字段key值为所输入关键字的所有记录数。输出界面如图所示。

请完善横线处的代码,实现将resut数据表中字段key值为txt(网页表单输入的关键字字符)的记录保存到列表变量rec中,并统计数量保存到sum中。
from flask import Flask, render_template
import sqlite3
#打开Flask网页模板和打开数据库并建立conn对象等代码略
app= Flask(_ name_ )
app.config['SECRET_KEY']='xxx_Sss_ 1276589'
bootstrap = Bootstrap(app)
class NameForm(FlaskForm):
txt = StringField('查询:', validators=[DataRequired( )])
submit = SubmitField('搜索')
@app.route(/)
@app.route('/cx', methods=['GET', 'POST'])
def index_cx( ):
rec=[ ]
sum= 0
cu = conn.cursor( ) #建立游标对象
rec = #使用fetchall( )函数将结果保存到列表rec中
sum = #统计列表变量rec的数量
conn.commit( ) #执行数据库语句
ru.close#关闭游标对象
conn.close
return render_ template('t4.html', form-myform, txt=sum)
if _name_ ='_main_':
app.run( )
from flask import Flask,render_template,request
app = _____________
@app.route("/")
def index():
#显示“主页”页面,代码略
@app.route("/introduce")
def introduce():
#显示“介绍”页面,代码略
@app.route("/exercise",methods=["GET","POST"])
def exercise():
#显示“练习”页面,代码略
@app.route("/top")
def toplist():
#显示“排行榜”页面,代码略
if __name__ == "__main__":
app.____________
-
(1) 请在划线处补充代码。
-
(2) 请用实线将下列访问的“在线加法练习系统”功能的URL与相应的路由及视图函数连接起来。(答案填写格式如:A-d 、B-a)
A.//127.0.0.1:5000/top
toplist()
a.@app.route("/top")
B.//127.0.0.1:5000/
exercise()
b.@app.route("/exercise",methods=["GET","POST"])
C.//127.0.0.1:5000/exercise
introduce()
c.@app.route("/introduce")
D.//127.0.0.1:5000/instance
index()
d.@app.route("/")
、、、
-
(3) 在Flask Web应用框架中,可以通过网页模板来显示内存变量的值或对象等,以下在模板文件index.html中用于显示内存变量xxjs值的正确代码为A . {{xxjs}} B . {{#xxjs#}} C . {{%xxjs%}} D . {%xxjs%}

![]()
请在划线处填入合适的代码。
s=input("请输入波群(m)")
a=[]
s=s+","
for j in range(len(s)):
if s[j] == ",":
t = float(s[i:j])
a.append(t) #append方法用于在列表末尾添加新元素
a.sort(reverse = True) #将a列表中的元素从大到小排列
sumbg=0
for k in range(len(a)//3):
sumbg = sumbg + a[k]
print("有效波高(m):",aver)
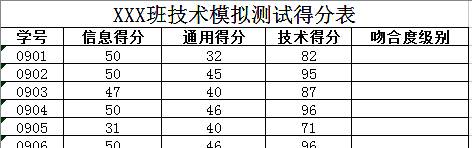
-
(1) 为了后续程序处理,我们需要把数据读入到程序中,每个学生一条记录,用python存储学生测试得分数据下列可行的是(以前两条记录为例) ;A . students=[[0901,50,32],[ 0902,50,45],……] B . students={'0901':['50', '32'], '0902':['50', '45'],……} C . students={0901:['50', '32'], 0902:['50', ' 45'],……} D . students=[['0901', '50', '32'],['0902', '50', '45'],……]
-
(2) 编写函数f(xx,ty)实现传入信息得分和通用得分,返回吻合度级别(返回示例:'1 级偏差')
-
(3) 完成程序填空:
students={'0901':[50,82],'0902':[50,95],……} #(以前两条记录为例)
for i in students.keys():
xx=
ty=
print(i,':',f(xx,ty))
|
图 a 图 b |
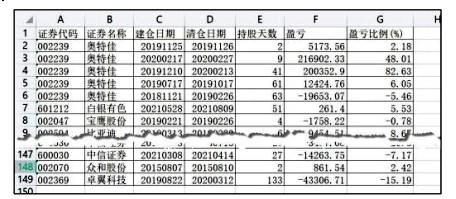
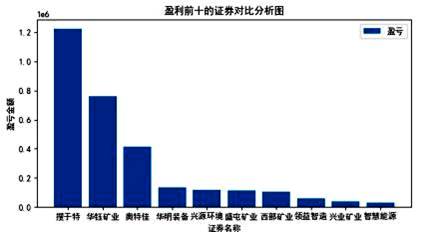
该投资者为了总结投资经验,编写如下程序, 对数据进行分析。请在划线处填入合适代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #使图形中的中文正常编码显示
df = pd.read_excel ("table.xlsx")
print( ) print( )
#筛选出所有盈利的证券操作记录。
#输出表格中所有操作的总盈亏。
#以下代码功能为找出盈利最大的 10 只证券, 并呈现如图 b 所示的图表。
g = df.groupby("证券名称",as_index = False)
df1 = g.盈亏.sum()
df1 =
print(df1[:10])
plt.figure(figsize = (8,4))
plt.title('盈利前十的证券对比分析图')
plt. (df1[:10].证券名称,df1[:10].盈亏,label = "盈亏")
plt.xlabel('证券名称')
plt.ylabel("盈亏金额")
plt.legend() #显示图例
plt.show ()
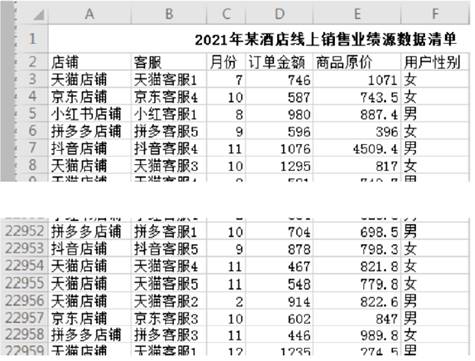 图a
图a
使用Python读取表格中的数据,代码如下,根据题意填写划线部分:
import pandas as pd
df=pd.read_excel("销售.xlsx")
print() #筛选出商品原价大于等于1000的记录。
df1=df.groupby("客服",as_index=False)["订单金额"].sum()
df1.rename(columns={"订单金额":"订单总额"},inplace=True)
df2=
print( df2 ) #按“订单总额”降序排序后输出前10条记录
#以下代码功能为:绘制“各月份销售额”的折线图,结果如图b所示。
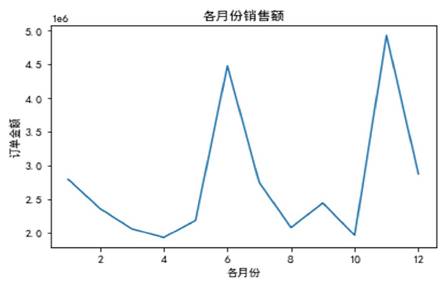 图 b
图 b
import matplotlib.pyplot as plt
df3=df.groupby("月份",as_index=False)["订单金额"].sum()
plt.figure(figsize=(10,5))
plt.title('各月份销售额')
plt. (df3["月份"],df3["订单金额"])
plt.xlabel('各月份')
plt.ylabel("订单金额")
plt.show( )
| 序号 | 书店名称 | 图书名称 | 销量 | 单位 |
| 1 | 新华书店 | 三国演义 | 41 | 本 |
| 2 | 学仁书店 | 十万个为什么 | 32 | 本 |
| 3 | 学仁书店 | 红楼梦 | 36 | 本 |
| 4 | 联合书店 | 弟子规 | 21 | 本 |
用Python程序对数据做了整理与分析:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"] #用于显示中文标签
data=pd.read_excel("图书销量表.xlsx")
data=data.drop(2,axis=0)
s=data.sort_values("销量",ascending=True)
plt.bar(s.图书名称,s.销量,label="销量")
plt.title("各图书销量比较",fontsize=26) #设置图表标题
plt.legend()
plt.show()
上述代码运行后,输出的结果为
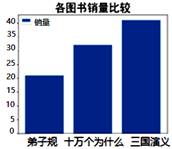 B .
B . 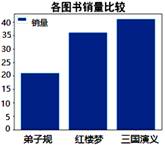 C .
C . 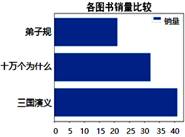 D .
D . 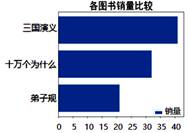
| 图 1 | 图 2 | 图 3 |



from PIL import Image
1 import numpy as np
2 import matplotlib.pyplot as plt
3 img=np.array(Image.open('dog.jpg').convert('L'))
4 row,cols=img.shape
5 for i in range(row):
6 for j in range(cols):
7 if img[i,j]>188:
8 img[i,j]=1 #1表示白色
9 else:
10 img[i,j]=0 #0表示黑色
11 plt.figure('dog')
12 plt.imshow(img,cmap='gray') 13 plt.axis('off')
14 plt.show()
1)在⽐赛场地上放置了n个硬币,每个硬币的位置均不相同,各位置坐标(x,y)保存在⽂本⽂件中(如图所示,放置了5个硬币,⽂本中坐标按x,y升序排列);
2)机器⼈在两个硬币位置间⾛直线,从起点(0,0)出发,按硬币x坐标从⼩到⼤去捡,若x坐标相同,则按y坐标从⼩到⼤捡;取⾛其中的n-1个硬币,总⾏⾛距离最短的机器⼈将获得⽐赛的冠军。
例:如图a所示,p2直接到p4则代表p3处硬币未取。
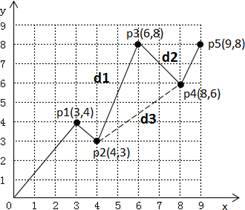 图a
图a
 图b
图b
![]() 图c
图c
完成该项⽬分以下⼏个步骤:
-
(1) 读取坐标数据。
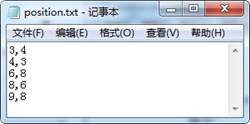
从⽂本⽂件中读取硬币的坐标(x、y),分别存储在列表 x 和y 中。请在划线处填⼊合适的代码。
f=open("position.txt",'r') #从⽂件中读取坐标位置
x=[0]; y=[0] #将原点坐标分别存储在x、y 列表中
line=f.readline() #取出一⾏数据
#从⽂本⽂本中读取硬币的位置,并存储在 x、y 列表中
while line:
data=line.split(",") #以逗号为分隔符转换成列表
x.append(int(data[0]))
line=f.readline( )
f.close() #关闭⽂件
-
(2) 编写函数,计算两点间的距离。请在划线处填⼊合适的代码。
from math import sqrt
def dist(x1,y1,x2,y2): #计算(x1,y1)到(x2,y2)的距离
d=
return d
-
(3) 设计算法与程序实现。
机器⼈取⾛n-1个硬币经过的最短距离公式可以描述为:
其中:为机器⼈取⾛n-1个硬币⾛的最短距离;为机器⼈取⾛n个硬币经过的距离之和;为机器⼈未取第i个硬币少⾛的路程;Max为求中的最⼤值。
根据上述算法编写的Python程序如下,请在划线处填⼊合适的代码。
n=len(x) : long=0
for i in range(1, n):
long=long+dist(x[i-1], y[i-1], x[i], y[i])

ansi=n-1
for i in range(2, n):
d1=dist(x[i-2],y[i-2],x[i-1],y[i-1])
d2=dist(x[i-1],y[i-1],x[i],y[i])
d3=dist(x[i-2],y[i-2],x[i],y[i])
dx= #计算未取第i-1 个硬币少⾛的路程。
if dx>maxd:
maxd=dx
ansi=i-1
print("机器⼈⾏⾛的最短距离为:"+str(round(, 4))) print("未取⾛的硬币的位置为:(",x[ansi],",",y[ansi],")")
-
(4) 调试和异常处理
当最后一个硬币未取为最短距离时,上述程序运⾏结果不正确。加框处代码有误,请修改。

-
(1) 小明对数据进行了整理,下列操作不恰当的是( )(单选,填字母)。A . 发现记录中有6 条重复,对这6 条记录进行了删除 B . 发现记录中有38 处数据项缺失,直接删除相关记录 C . 将某条记录中订单日期“2050-6-9”订正为“2021-6-9” D . 将某条记录中订单日期“2021#3#11”修改为“2021-3-11”
-
(2) 小明发现数据中仍有极少量时间段外的记录混杂其中,利用Python 及pandas 模块进行处理。请回答问题:
① 采用pandas 模块中的(单选:填字母:A .Series / B .DataFrame)
数据结构存储全部数据会比较高效。
② 全部数据保存于变量df 中,为筛选出订单日期为2021 年第一季度内的所有记录,
可以执行Python 语句df1 = ,则df1 中保存筛选结果。(单选,填字母。
提示:多条件筛选时,条件之间用“&”连接,表示需要同时满足这多个条件)
A.df[ (df['订单日期'] <= '2021-1-1' ) & (df ['订单日期'] <= '2021-3-31') ]
B.df [ (df ['订单日期'] >= '2021-1-1') & (df ['订单日期'] >= '2021-3-31') ]
C.df [(df ['订单日期'] >= '2021-1-1') & (df ['订单日期'] <= '2021-3-31')]
-
(3) 经过以上两步处理之后,为了解“所在地市”第一季度“订购数量”前10 名的情况,
编写如下Python 程序段:
#数据整理结果保存于变量df1中,代码略
g = df1.groupby('所在地市', as_index = False).sum()
print )

则划线处的代码可为( )(多选,填字母)
A . g.sort_values('订购数量',ascending = False) [0:10] B . g.sort_values('订购数量',ascending = True).tail(10) C . g.sort_values('订购数量',ascending = True)[0:10] D . g.sort_values('订购数量',ascending = False).head(10) -
(4) 根据以上数据整理结果,小明对第一季度所在地市的“订购数量”进行可视化处理,如图b所示。
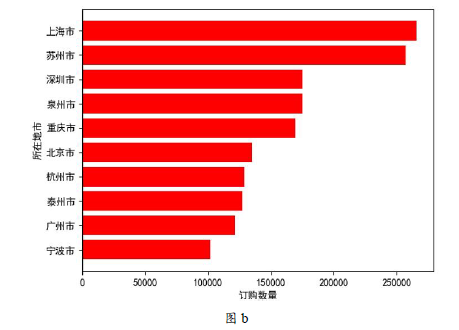
实现上述功能的Python程序部分代码如下:
#按“所在地市”对第一季度数据分组并求和,再按“订购数量”升序排序
#选取最后10条数据,存入变量s,代码略
import matplotlib.pyplot as plt
x = s['所在地市']
y =
plt.barh(x, y, color = 'r')
plt.show( )
程序中划线处代码应为。
-
(5) 小明借助大数据技术,对近几年来该网络购物平台的日用化妆品销售数据进行了分析。
应用该分析结果可能提供的数据服务是(列举一条即可)。
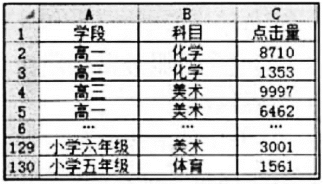
import pandas as pd
df=pd. read_excel ('微课点击量.x1sx')
df1=df. group by("科目", as_index=False). sum()
df2=



