网络应用模式 知识点题库
-
(1) 试列表比较B/S架构与C/S架构的优缺点。
架构
优点
缺点
C/S架构
B/S架构
-
(2) 你认为B/S架构会完全替代C/S架构吗?请简述理由。
①用浏览器访问该系统时,会显示欢迎页面,其中包含“关于”“练习”及“排行榜”三个链接。
②单击“关于”链接进入系统介绍的页面。
③单击“练习”链接进入练习的页面,其中显示由计算机随机生成的两个整数,整数的范围为[1,100]。如果练习者输入的答案正确,那么应用自动给出新题;若输入的答案错误,则应用提示答案错误并要求重新输入答案。
④单击“排行榜”链接进入排行榜页面,显示得分排行榜。
-
(1) 在规划设计“在线加法练习系统"的过程中,小明根据需要选择了一种基于Python语言的Web应用框架。请你为小明选择一种Web应用框架并简单描述该框架的特点。
①常见的基于Python语言的Web应用框架:① ②③
②你选择的Web应用框架:
③使用该框架编写的网络应用架构为(选填:“B/S架构”或“C/S架构”)。
④该Web应用框架特点:
-
(2) 根据“在线加法练习系统”的功能需求,实现网页跳转、习题生成答案输入及答案批改等功能,需在网络应用程序中导入的模块有:
实现的功能
使用的模块
模块中的对象
构建Flask应用实例
flask
Flask
使用网页模板构建应用网页
处理网页请求的对象
创建并处理网页表单
用于表单字段定义及验证
生成[1,100]范围内的整数
移动互联网的发展,极大地方便了人们的社会生活。某同学使用智能手机APP,查询某天的列车时刻、始发站、终点站、经停站、余票、票价等信息,购买了一张高铁车票。

该同学网络购票所使用的信息系统采用的体系结构是结构(模式)。
|
图1 |
图2 |
图3 |
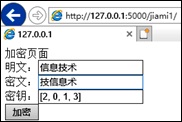
选择加密时,在明文文本框中输入明文,点击“加密”按钮,网页显示密文与对应的密钥。加密规则为打乱明文对应的索引作为密钥,再利用该索引逐个取明文字符连接成密文,例如:明文为“信息技术”,若被打乱的索引为[2,0,1,3],则密文为“技信息术”,密钥为“2,0,1,3”
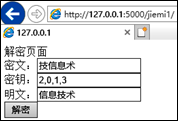
选择解密时,在密文文本框中输入密文,密钥文本框输入密钥,点击“解密”按钮,网页显示明文。
-
(1) 该网络应用属于架构。(单选,填字母:A . B/S架构,B . C/S架构)
-
(2) 若待解密文本为“自息爱信也我己爱”,密钥为“2, 7, 1, 6, 4, 0, 3, 5”,则解密结果是。
-
(3) 实现该功能的python程序如下,请在划线处填入合适的代码:
from flask import render_template,request,Flask
import random
app=Flask(__name__) #创建应用实例
@app.route('/') #选择页面路由
def index():
return render_template('')
#加密功能代码略,以下为解密代码:
@app.route('/jiemi1/',methods=["GET","POST"])
def jiemi1():
wb=request.form["wb"] #利用request获取网页文本框内容,返回示例:“1,4,2,3,0”
keyo=request.form["key"] #变量wb存储密文,变量keyo存储密钥
keyn=list(map(int,keyo.split(","))) #将字符串keyo转换为数值列表,示例:[1,4,2,3,0]
result=""
for i in range(len(keyn)):
for j in range(len(keyn)):
if :
break
result+=wb[j]
return render_template("jie.html",WB=wb,KEY=keyo,RESULT=result)
if __name__=="__main__":
-
(4) 根据上述描述与图1,则“天气”节点中的“多云”信息熵是。
-
(5) 实现求首次划分节点的程序如下,请在划线处填入合适的代码:
def cal(lst): #计算样本lst的信息熵
x,y,z=0,len(lst),0 #x表示该样本信息熵,y表示该样本数量,z表示某信息发生的概率
num={}
for i in lst:
if i not in num:
num[i]+=1
for k in num:
z=num[k]/y #计算该信息发生的概率
x-=z*log(z,2) #根据公式计算信息熵,log(b,a)等价于logab
return x
def check(x,y):
#根据节点x,对样本y进行划分,返回示例:{'否': [1, 1, 0, 0, 1, 1, 1, 1], '是': [1, 1, 0, 1, 0, 0]}
dic={'是否有风': ['否', '否', '否', '否', '否', '否', '否', '否', '是', '是', '是', '是', '是', '是'],
'天气': ['多云', '多云', '晴', '晴', '晴', '雨', '雨', '雨', '多云', '多云', '晴', '晴', '雨', '雨'],
'温度': [28, 27, 29, 22, 21, 21, 20, 24, 18, 22, 26, 24, 18, 21],
'湿度': [78, 75, 85, 90, 68, 96, 80, 80, 65, 90, 88, 63, 70, 80],
'是否前往': [1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0]}
xm=list(dic.keys())
entropy=cal(dic[xm[-1]]) #调用函数计算样本原始信息熵entropy
#计算各节点信息增益
m=0;p=""
col=xm[:-1] #“是否前往”是结果项,不参与计算
for i in col:
size=len(dic[i]);entropy_1=0
zyb= #调用函数对样本按照当前节点进行划分
for j in zyb: #根据划分情况逐个求子样本信息熵并按比例累加
entropy_1+=len(zyb[j])/size*cal(zyb[j])
zy=entropy-entropy_1
print(i,"的信息增益:",zy)
if zy>m: #计算最大信息增益与信息增益最大的节点
m=zy
print("信息增益最大的节点:",p)



